
O que esperar da IA em 2024
dezembro 20, 2023 § Deixe um comentário
Descubra as principais tendências em IA para 2024, desde a escassez de GPUs até o avanço da IA generativa e o aumento da capacidade de trabalho.

O último ano foi marcado pela popularização da IA generativa, com termos como ChatGPT e Bard caindo na “boca do povo”. Também pudemos assistir enormes investimentos na área, como por exemplo os US$10 bilhões que a Microsoft colocou na OpenAI [1] e os US$4 bilhões da Amazon na Anthropic [2]. Enquanto pesquisadores e CEOs debatiam a probabilidade da Inteligência Artificial Geral (na sigla em inglês AGI – Artificial General Intelligence) em redes sociais e manchetes de jornais e revistas [3], os criadores de políticas públicas começaram a levar a sério a regulamentação da IA – a União Européia apresentou o conjunto mais abrangente de políticas que regem a tecnologia até agora [4] e o governo Biden publicou uma Ordem Executiva detalhando 150 requisitos da área para agências federais [5].
Se você tem interesse em IA, 2024 promete ser tão movimentado quanto 2023. Longe de mim querer brincar de cartomante, mas há algumas tendências que vale ficar de olho nos próximos 12 meses. Elas podem impactar tanto no desenvolvimento da área quanto no dia a dia das pessoas. São tópicos que ficarei ligado e que gostaria de compartilhar com vocês. Vamos a eles:
Leia o texto completo em Update or Die. Publicado em 20/12/2023.
A Conservação da Evidência Esperada e as narrativas
novembro 23, 2023 § Deixe um comentário
Depois da prisão de uma mulher acusada de bruxaria, se ela estivesse com medo, isso provaria sua culpa; se ela não estivesse com medo, isso também provaria sua culpa

Friedrich Spee von Langenfeld foi um padre jesuíta alemão que ouvia confissões de bruxas condenadas. Era um crítico do processo penal da inquisição e de sua caça às bruxas. Em 1631 escreveu um livro chamado “Cautio Criminalis” (algo como “prudência em casos criminais”), no qual descreveu de forma mordaz a árvore de decisão para condenar bruxas.
Segundo Spee, a coisa ia mais ou menos assim:
Se a bruxa tivesse levado uma vida má e imprópria, ela era culpada; se ela tivesse levado uma vida boa e adequada, isso também seria uma prova da sua culpa, pois as bruxas dissimulam e tentam parecer especialmente virtuosas. Depois da prisão de uma mulher acusada de bruxaria, se ela estivesse com medo, isso provaria sua culpa; se ela não estivesse com medo, isso também provaria sua culpa, pois as bruxas caracteristicamente fingem inocência e são “caras-de-pau”. Ou ainda, ao ouvir uma denúncia de bruxaria contra ela, a mulher acusada tinha duas opções: poderia fugir ou permanecer; se ela fugisse, isso provaria sua culpa; se ela permanecesse, foi o diabo que a deteve para poder reivindicar sua alma.
Leia o texto completo em Update or Die. Publicado em 22/11/2023.
Computação Quântica 101: é um tipo de mágica
outubro 30, 2023 § Deixe um comentário
A computação quântica tem o potencial de revolucionar a segurança digital. Descubra como o algoritmo de Shor pode um dia “quebrar” a internet.

Ao sentar para escrever essas linhas, me veio à mente os primeiros versos da canção do Queen: “It’s a kind of magic, it’s a kind of magic, a kind of magic (No way)”. Antes de explicar o motivo, vale lembrar que este é o sexto texto de uma série em andamento sobre computação quântica. Os textos anteriores podem ser encontrados na numeração correspondente a seguir: 1, 2, 3, 4 e 5.
As bases da computação quântica foram lançadas em 1981 pelo físico Richard Feynman em uma lendária palestra. Posteriormente, Feynman elaborou sua fala em um artigo publicado no International Journal of Theoretical Physics. Lá ele pontuou que a construção de dispositivos de computação baseados em princípios quânticos poderia desbloquear poderes muito maiores do que os dos computadores clássicos.
Leia o texto completo em Update or Die. Publicado em 28 de outubro de 2023.
A moratória de 6 meses da IA… fez 6 meses
setembro 22, 2023 § Deixe um comentário
Há 6 meses, uma carta assinada por acadêmicos e executivos pediu uma pausa na IA. Gary Marcus lista o que mudou e o que não mudou desde então.
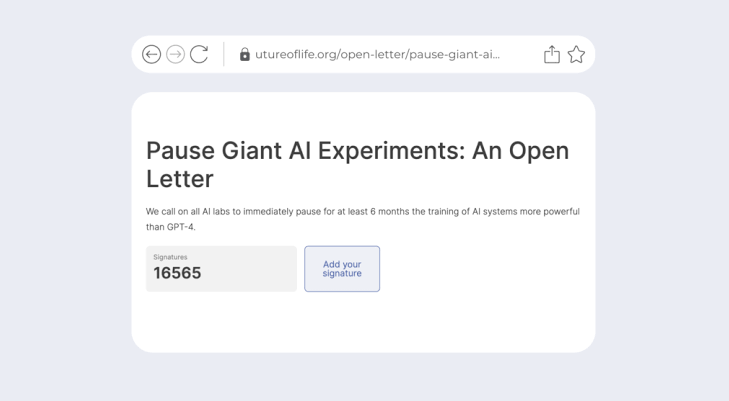
Penso que a maioria deve se lembrar da carta, assinada por milhares de acadêmicos e executivos de tecnologia, pedindo uma “pausa” de 6 meses na pesquisa e desenvolvimento de Inteligência Artificial (IA). Pois é, já faz 6 meses. Fui lembrado essa manhã pelo Gary Marcus, um dos que assinaram a carta. Eu também assinei, mas confesso que me arrependi pouco tempo depois.
Embora as razões do meu arrependimento sejam mais do que confessáveis (percebi que era mais uma estratégia dos que estavam atrás nas pesquisas do que uma preocupação genuína), não vem ao caso explorar essa linha argumentativa neste texto. Gary me listou em um e-mail o que ele considera que mudou e o que não mudou depois da moratória. E isso é mais interessante do que minhas reclamações.
Leia o texto completo em Update or Die. Publicado em 22 de setembro de 2023.
Grothendieck e o estado criativo solitário
agosto 4, 2023 § Deixe um comentário
A capacidade de levantar questões diferenciava Grothendieck, mais do que sua capacidade de respondê-las.

Há muitos anos estava com um grupo, que incluía o matemático Artur Ávila, almoçando na cafeteria do IMPA. A conversa girava em torno do tema “criatividade”. Em dado momento, Ávila pergunta: “já leu Récolte et Semailles do Alexander Grothendieck?”. Respondi que não. Ávila então, enigmaticamente, completou: “Então leia”.
Por alguns anos deixei de lado o conselho e fui cuidar da minha vida.
Leia o texto completo em Update or Die. Publicado em 04 de agosto de 2023.
O Brasil e a onda da inteligência artificial generativa
março 6, 2023 § Deixe um comentário
Em breve estaremos bem abastecidos com serviços de IA generativos concorrentes e de rápida melhoria e nadaremos nos oceanos de conteúdo que eles produzirão. E o Brasil, como vai surfar essa onda?

O ChatGPT, apesar de ainda não ser um produto totalmente finalizado e sim uma iteração inicial de inteligência artificial generativa – IA que produz conteúdo original em vez de simplesmente agir ou analisar dados existentes – teve sua nova versão lançada na primeira semana de março pela OpenAI.
Há muito mais ainda por vir. O Bing, da Microsoft, lançou sua versão argumentativa e emocional do ChatGPT há algumas semanas. A Google está trabalhando no Google Bard, seu concorrente para o ChatGPT. A Meta afirma ter uma versão, mas ainda não decidiu se a lançará. A chinesa Baidu espera lançar seu serviço este mês, assim como a ferramenta de busca sul-coreana Naver.
Leia o texto completo em Update or Die. publicado em 06 de março de 2023.
Reiniciando a IA
março 1, 2023 § Deixe um comentário
Tomei emprestado o título desse texto de um livro publicado pelo Gary Marcus e pelo Ernest Davis em 2019, chamado Rebooting AI . Apesar da “homenagem”, o texto não é propriamente sobre o livro, embora ele seja uma das referências, é sobre o zeitgeist da maioria das pessoas que estão pesquisando e desenvolvendo a IA atual.

Imagem de upklyak no Freepik
Tenho refletido bastante, de 2021 para cá, em como abordar esse assunto para um público mais abrangente. Uso mais ou menos matemática? Mais ou menos conceitos teóricos? Mais ou menos exemplos práticos? O quanto de computação preciso mostrar? Vale a pena incluir códigos de programação? Enfim, são algumas das muitas dúvidas que passaram (e ainda passam) pela minha cabeça.
Mas uma das (poucas) certezas que tenho tido, é da necessidade de tentar passar o “espírito do tempo” que conduz o desenvolvimento da IA. Principalmente porque as discussões que direcionam a inteligência artificial são (quase que) exclusivamente feitas na língua inglesa. Fato que deixa de fora não apenas boa parte da população brasileira, mas também mundial.
Leia o texto completo no LinkedIn. Publicado em 01 de março de 2023.
For an English version, read on Medium or Substack.

A sensação de se viver no “Velho Oeste”
fevereiro 16, 2023 § Deixe um comentário
No início de janeiro, especulou-se que a criação de uma fazenda de trolls usando uma versão customizada do GPT-3 poderia ser feita por cerca de meio milhão de dólares. A estimativa estava errada: usando o supra-sumo da IA atual, custa menos de quinhentos dólares.

Perdi o sono bem cedo hoje de manhã. Ingenuamente, achei uma boa ler meus e-mails. Quem sabe, me dá sono novamente, pensei. Ledo engano. Duas coisas com as quais tenho me preocupado nos últimos meses vieram me assombrar mais cedo do que esperava.
A primeira dela, que já externei em textos que escrevi sobre LaMDA, IAs de nível humano e método Transformers (a base do GPT-3 e ChatGPT), era que grandes modelos de linguagem pudessem ser cooptados por atores mal-intencionados para produzir desinformação em grande escala, usando modelos treinados sob medida.
Leia o texto completo em Update or Die. Publicado em 16 de fevereiro de 2023.
My Covid-19 dataset
janeiro 30, 2023 § Deixe um comentário
It was set to keep tabs on the Covid-19 spreading in Brazil
Source: OPAS.
At the start of Covid-19 pandemic, as most people in the world I suppose, I became pretty worried and anxious regarding its outcome. Being a data scientist, I initially used my skills to predict its spreading. I devised a predictive modeling based on Taylor series using the first and second derivatives of the continuous approximation of the usage data. The reason to use this method was due to the shortage of data at the time regarding the virus’s spreading pattern.
During a few months I got a decent forecast (you can check the report that I kept at the time on my personal blog here). Despite that I decided to discontinue the model at the time due a lack of emotional strength — I felt like a sort of Nostradamus at the time, foreboding doom, though I kept a daily update of the number of cases and deaths.
Anyway, there is always a time to call it a day, and for months I couldn’t decide how to call this shot. So, I decided to keep it going until I had access to daily updates. During most of the pandemic, the Brazilian press created a media consortium to consolidate the total of cases and deaths, since the Brazilian government at the time decided to withhold this information.
The consortium disbanded on January 28, 2023 after more than 80% of the population was fully vaccinated and the cases and deaths reached a stability. In this sense, I decided to consolidate the dataset and make it public. Anyone can have access to it at my GitHub repo (https://github.com/marcelo-tibau/covid-19). It was a long journey, but I confess that I am neither relieved nor satisfied. Maybe because it was a daily routine to retrieve the data for more than a 1,000 days or because I still hold my horses regarding the pandemic. Anyway, I hope sooner than later we all could sign in relief and breath undaunted as this pandemic becomes part of History books.
For a portuguese version, read at Update or Die.
You can also read it (or listen it) at:
Accounting for the knowledge gained during a web search: An empirical study on learning transfer indicators
janeiro 17, 2023 § Deixe um comentário
My new research paper published at Library & Information Science Research.
Marcelo Tibau, Sean Wolfgand Matsui Siqueira, Bernardo Pereira Nunes, Accounting for the knowledge gained during a web search: An empirical study on learning transfer indicators, Library & Information Science Research, Volume 45, Issue 1, 2023, 101222, ISSN 0740-8188, https://doi.org/10.1016/j.lisr.2022.101222. (https://www.sciencedirect.com/science/article/pii/S0740818822000858).
Abstract: Searches with learning intent typically require the users to interact with the searching environment and perform knowledge acquisition features such as scan, read, and process the online content to fulfill their information needs. To capture indicators from searching behaviors that could account for the knowledge gained during a Web search, a qualitative study was performed using the Concurrent Think-Aloud protocol to observe the mechanisms of transfer and map knowledge flows during 78 search sessions. Findings indicate evidence of transfer of learning in the form of sixteen online information searching strategy indicators. This research aids the understanding of how knowledge is gained during search sessions and how to identify behaviors that could indicate that learning has occurred, which could be used to represent knowledge gain on Web search engines. In this way, it can aid search engines to become not only better tools of searching, but also tools of learning.
Keywords: Constant comparative method; Concurrent think-aloud protocol; Transfer of learning; Knowledge gain; Web searching.
To get access to the article, use the share link: https://authors.elsevier.com/a/1gRKl2eSLIkd3Q
#research #informationscience #learning #searchengines

